Human Aided Agent Training
A study on how AI Agents can become interfaces for human learning.

Introduction
In computing, an interface is a shared boundary across which two or more separate components of a computer system exchange information. The exchange can be between software, computer hardware, peripheral devices, humans, and combinations of these.
Through this experiment we aim at answering the question, can Artificial Intelligence serve as an interface between humans? Specifically, we asked, can an AI agent learn a task directly from an (expert) human and to what extent, and if so, once trained, can it teach the task back to a (novice) human?
The project is still in progress and this serves as an account of our progress so far.
Team
- Prabhav Bhatnagar
- Yugvir Parhar
My Role
My role was primarily the design of the experiments and implementation of the same on Unity3D. I handled environment setup and programming of the functionalities along with major VR interactions.
Tech Stack
- Unity3D
- ml-agents
- OcculusVR
Initial Research
We started off by exploring algorithms and experiments which would be able to achieve this goal. We settled on using the ml-agents package by Unity for it would allow us to easily set up our experiment and explore Reinforcement Learning and Imitation Learning. As an abstract idea, we planned on creating a VR table tennis game that we would teach an AI agent through demonstration and once trained to an appropriate level, we would test its performance against humans.
That was easier said them, after a quick prototype, we realized that the idea would be too complicated to execute, so we decided to scale down and fundamentally think about the problem. It was here that I developed my 3 phase implementation technique. Toy-Test-Trial.
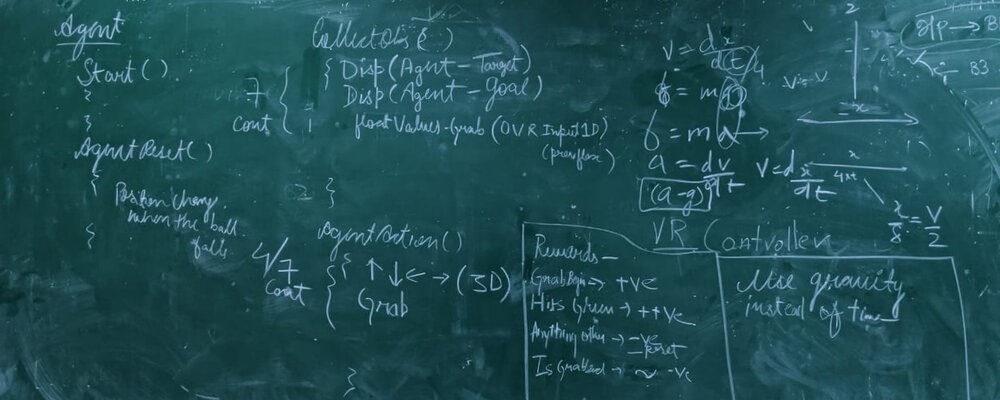
Breaking It Down
Let’s talk a bit about Reinforcement Learning and Imitation Learning.
Reinforcement Learning
In layman terms, is the training of an agent to take actions informed by the observations from the environment and receiving an appropriate reward in response. It must learn to perform actions that maximize the cumulative reward, thus leading it to its desired goal.
Imitation Learning
On the other hand, is best summarized as ‘monkey see, monkey do’. It works the principle of behavioral cloning which is irrespective of rewards.We theorized that to its core, the information the agent needed to learn was
- Its translational information (XYZ)
- Its linear velocity
- Its rotational information (yaw, pitch, roll)
- It’s torque
- Its position with respect to the target (ball).
So let’s break this down to toy, test, and trial
- For the toy task, we give the agent 2 degrees of freedom (XZ).
- For the test task, we give the agent 3 degrees of freedom (XYZ).
- For the trial task, we give the agent 5 degrees of freedom (XYZ pitch and roll).
Note: yaw is redundant owing to symmetry.

Experiment setup
The Virtual Training setup contains a paddle that must learn to continuously bounce against it a pong ball without letting it drop to the floor. The paddle has a Degree of Freedom of 5, it can translate in X, Y and Z axes (3 units in all the respective directions), and it has the ability to perform pitch and roll (Rotate along X, and Y axes). There are 4 important colliders present, on the ball, on the paddle, on the ground and an invisible collider above the a certain threshold to register juggling. The ball is instantiated randomly (range of (-1 to 1)) above the XY plane at various angles to the plane. Rewards are provided in contact with the colliders (see "Experiment Design").
The agent takes an array of five elements as controls. The elements in order are X, Y, Z axes, pitch, and roll with each being able to take a value from -1 to +1. The paddle makes constrained movements ranging from -3 to 3 units in X and Z axes, 0 to 3 in the Y-axis, and the pitch and roll are not constrained. In the VR environment, for Imitation learning, the controls are mapped to the Oculus hand Controllers.
There are a total of 15 states:
- The position vector of the paddle, i.e, x[1], y[2], z[3] coordinates of the paddle.
- The position vector of the ball, i.e, x[4], y[5], z[6] coordinates of the ball.
- The velocity of the paddle, i.e, a vector3 containing magnitude[7] and direction[8 9 10].
- The velocity of the ball, i.e, a vector3 containing magnitude[11] and direction[12 13 14].
- The distance between the paddle and the ball[15].
The rules for the awarding rewards are:
- +5 rewarded when the ball hits ”PositiveRewardZone” (a collider above the ground plane).
- -0.1 for every frame the ball is being balanced on the paddle and not being jugled.
- -1 if the ball hits the ground
The reward is set to 0 once the ball hits the ground and the environment is reset
Approach/ Control Model
The control training method employed was to use Reinforcement Learning with PPO optimization for an environment where the agent had 5 degrees of freedom. It is apparent that using simple Reinforcement Learning was too complex a problem to be trained in a few hours. Thus, we broke the problem into two parts to reduce complexity. One part would be to learn the axes’ translation and another to learn the rotation aspects.
Experimental Model 1:
The first model consisted of using Reinforcement Learning for only part of the problem, i.e, for 3 degrees of freedom(the X, Y and Z axes translation). This model, in 300 thousand iterations performed drastically better than the control which took 1 million iterations for subpar performance and a maximum score of 3.
Experimental Model 2:
This model was also trained for 3 dof and differed from Experimental Model 1 in that it made use of Recurrent Neural Networks in the form of "Long Short Term Memory"(LSTM) architecture. It performed exceptionally better than experimental model 1.
Experimental Model 3:
A third model is a novel approach wherein training of two different models is done, one akin to ”Experimental Model 2” and the other that learns the Rotation actions (pitch and roll) via demonstrations provided by the trainer, using the Virtual Reality controller to map the rotation input. Then, we use the brains simultaneously to act on the agent to perform the task.
Results:
Here is an overview of the project. I have also provided videos for the individual performances of all the models!
Here is the performance of the Control Model with 5 degrees of freedom. As expected, it failed to learn the task properly due to the high complexity of the problem.
Here is the performance of the model when given only 3 degrees of freedom (Experimental Model 2). As expected, it has learned the task completely due to the low complexity of the problem.
Here is the performance of the novel model (Experimental model 3) when given 5 degrees of freedom. It has learned the complex task with an improved level of performance when given the same task to perform in Virtual Reality.
Challenges:
- Identifying the novel mechanism for utilizing differently trained models simultaneously that would satisfy the task proved to be very difficult, I overcame this issue by ideating through all the various split-ups of the problem.
- The ML-Agents toolkit is still relatively new and does not offer as much freedom as we would have liked, for example, we could only use one type of optimizer and couldn’t experiment further. To compensate for that we used different Neural Network Architectures in combination with the Optimiser to maximize the possibilities of our study.
- The hyperparameter tuning took a huge portion of our timeline for the project.
- Lack of online support for technical issues related to ML-Agents given its infancy.
- The expert had to be comfortable while demonstrating the task. The use of mouse and keyboard proved erroneous. So, we made use of VR to enable the expert to perform the task freely and more intuitively.
Impact
The results could enable the prospect of AI as an intermediary, where specialized tasks could be taught to AI agents that would in turn teach other actors. Industries which would reap great benefit from this research include but are not limited to Sports, Video Games and Robotics.
Achievement
Here is my teammate Yuvir Parhar showcasing our work as a poster presentation at IndiaHCI 2019 and the work also won Silver at SRM Research Day.


Future Work
With all that is done, there is quite some way to go, we plan on continuing the project by scaling the challenges and designing experiments which can allow clear testing of transfer of skills through AI. Imitation Learning on vr as a constraint has been solved in the newer build of ml-agents and would allow us to fledge out the vr functionality.